Domaines statistiques, plan d’échantillonnage et taille des échantillons
Étape 4
Les statistiques mesurées par le SMSS, telles que les taux de mortalité, peuvent être représentatives au niveau national ou au niveau provincial ou régional. Une puissance statistique plus importante peut être nécessaire dans certaines régions prioritaires. Il s’agit d’une décision clé pour le fonctionnement du système, ainsi que pour son coût. Une fois cette décision prise, il est possible de calculer la taille de l’échantillon.
Détermination des domaines statistiques de représentativité
En général, les pays souhaitent disposer de données au niveau de la plus petite unité de mise en œuvre sanitaire, telle que le district, afin de faciliter la prise de décision au niveau local. Toutefois, pour la mortalité et les résultats relativement rares, le coût de la production de données continues à chaque niveau de district peut être prohibitif. Il est essentiel que, lors de la conception du SMSS, un consensus soit trouvé sur le niveau de domaine auquel les estimations statistiques seront produites et considérées comme représentatives. Les domaines peuvent comprendre toutes les zones administratives de niveau 1 ou certaines d’entre elles, telles que les provinces et les régions, ainsi que certains districts pour lesquels le gouvernement et les parties prenantes souhaitent disposer de données afin de soutenir des programmes ciblés spécifiques. La stratification peut également être effectuée par zones urbaines et rurales. Certaines zones infranationales peuvent faire l’objet d’un suréchantillonnage afin de permettre une analyse désagrégée nécessaire et pertinente ou d’améliorer la précision des taux de mortalité ou d’autres indicateurs générés. Ces décisions doivent être prises en consultation avec le gouvernement, les parties prenantes et les institutions chargées de la mise en œuvre. Lors du choix du domaine, il est essentiel de garder à l’esprit que plus le nombre de domaines définis est élevé, plus l’échantillon final sera important et plus le système sera coûteux. Il faut trouver un compromis entre les ressources disponibles, la faisabilité de la collecte de données et le nombre de domaines, le tout en fonction de l’objectif des niveaux du système. Les autorités chargées de l’enregistrement doivent être consultées afin de s’assurer que les grappes d’échantillonnage sont sélectionnées en fonction de limites administratives significatives, utiles et adaptées à leurs besoins administratifs et opérationnels. Cette approche facilitera la collecte et l’analyse de données précises et, en fin de compte, l’amélioration des systèmes d’état civil.
Base d’échantillonnage
Une base de sondage est une liste complète et actualisée de petites unités géographiques couvrant l’ensemble du pays et comprenant des informations sur la population totale par unité (ou le nombre total de ménages) et les principaux stratifiant tels que les provinces/régions, les districts, les zones urbaines et rurales, les principales villes et les villages, etc. Les petites unités géographiques doivent être suffisamment petites pour servir de grappes géographiques pour le SMSS. Une base de sondage complète est nécessaire pour établir l’échantillon de grappes géographiques à partir duquel l’échantillon sera tiré. Une base de sondage issue d’un recensement récent de la population serait une source idéale pour un échantillonnage rigoureux. Il est important d’évaluer l’exhaustivité de la base de sondage et de définir clairement ce qui serait considéré comme un grappe. Une base de recensement de la population comprend la population et les ménages ventilés par zones de recensement (EA). Les EA comptent souvent entre 100 et 150 ménages, selon qu’il s’agit d’une zone urbaine ou rurale. Les EA peuvent être considérées comme des grappes. Cependant, les zones plus vastes qui comprennent 2 ou 3 EA peuvent être considérées comme des grappes géographiques afin de réduire le nombre de grappes nécessaires dans le SMSS, tout en permettant à un agent communautaire de visiter chaque ménage tous les 1 à 2 mois. Lors de la définition des grappes, il est essentiel de s’assurer qu’elles ont des limites bien définies et physiquement identifiables afin de faciliter la surveillance. Il est donc essentiel que les décisions concernant la constitution d’une grappe soient prises avec soin, en tenant compte de la disponibilité des données démographiques au niveau de la grappe, de la taille de la grappe et de ses limites. Il faut également garder à l’esprit que les grappes trop petites peuvent être instables au fil du temps et nécessiter des mises à jour démographiques plus fréquentes que les grappes relativement grandes.
Exemple COMSA/SIS-COVE
Au Mozambique, le SIS-COVE utilise des grappes composées de groupes de 2 à 3 EA qui ont été considérés comme des zones de contrôle lors du recensement de la population de 2007 et qui représentent environ 300 ménages. On s’attendait à ce qu’un recenseur résident puisse couvrir une zone de contrôle d’environ 300 ménages (environ 1 500 habitants). En réalité, la taille de la population variait considérablement d’une zone de contrôle à l’autre. Il a donc fallu diviser certaines zones de contrôle lors de la phase d’échantillonnage.
Conception de l’échantillon : sélection des grappes
Le plan d’échantillonnage doit tenir compte des domaines statistiques pris en considération, comme décrit à l’étape 3. La base de sondage doit être organisée en fonction des grappes définies (unités d’échantillonnage ou groupes d’unités d’échantillonnage, ou villages), couvrant de manière exhaustive tous les domaines et toutes les strates. Les stratégies de sélection des grappes au sein des domaines et des strates comprennent la sélection aléatoire simple ou l’échantillonnage en grappes à plusieurs degrés. Un échantillonnage aléatoire simple peut être approprié si les grappes sont toutes de taille similaire. Cette approche permettra d’obtenir un échantillon auto-pondéré qui ne nécessitera donc pas l’utilisation de pondérations d’échantillonnage. Cependant, cette approche peut produire un échantillon biaisé s’il existe de grandes différences de taille entre les grappes. En outre, un échantillon aléatoire simple, bien que plus efficace, peut ne pas être pratique pour l’équipe d’étude si les strates sont très grandes et si les grappes sont éloignées les unes des autres. Si les grappes diffèrent en termes de taille de population, l’échantillon peut être tiré à l’aide d’un échantillonnage aléatoire avec une probabilité proportionnelle à la taille. Cela nécessite de calculer des pondérations d’échantillonnage afin d’ajuster les estimations calculées à partir de l’échantillon. Les très grandes grappes peuvent être segmentées davantage, et un segment peut être sélectionné. Une alternative à l’échantillonnage aléatoire consiste à recourir à un échantillonnage à plusieurs degrés. Un échantillonnage en deux étapes consistera à sélectionner des districts au sein des provinces lors d’une première étape, puis à sélectionner des grappes au sein des districts sélectionnés. Ces étapes seront sélectionnées avec une probabilité proportionnelle à la taille en termes de population ou de nombre de ménages. Pour garantir la précision, l’échantillon doit être réexaminé et vérifié périodiquement afin de s’assurer qu’il est toujours représentatif des domaines initiaux. Les zones urbaines présentent des défis supplémentaires pour la surveillance. Souvent, la population des zones à statut socio-économique élevé n’est pas accessible à l’équipe de surveillance ; par exemple, elle peut se trouver à l’intérieur de communautés fermées. Cela est particulièrement vrai dans les capitales et les grandes zones métropolitaines. À l’aide des données du recensement de la population, les zones socio-économiques et administratives élevées et inaccessibles dans les grandes zones métropolitaines peuvent être identifiées et exclues de l’échantillon de grappes avant la sélection de l’échantillon. En général, on s’attend à ce que la population de ces zones soit faible. Dans la plupart des pays, il sera essentiel de travailler avec des experts de l’institut national de statistique qui connaissent bien la structure administrative du pays et la base de sondage et qui seront en mesure de donner des conseils sur la meilleure stratégie d’échantillonnage. Il est également essentiel de procéder à plusieurs essais d’échantillonnage avant d’aboutir à un échantillon satisfaisant. L’échantillon final doit également être discuté avec le ministère de la santé et les principales parties prenantes afin de s’assurer qu’il répond à leurs besoins et exigences spécifiques.
Calcul de la taille de l’échantillon
Des estimations de référence de la mortalité sont nécessaires pour déterminer le nombre de grappes et la taille de l’échantillon. Il convient d’utiliser des données fiables et récentes sur la mortalité aux niveaux national et infranational. Le choix d’un indicateur de mortalité et sa précision doivent être faits avec soin afin d’obtenir une taille d’échantillon suffisante pour estimer d’autres indicateurs prioritaires avec une précision acceptable. En règle générale, les indicateurs de mortalité infantile donneront une taille suffisante si une précision acceptable est utilisée. Les données des enquêtes démographiques et sanitaires peuvent être utilisées si une enquête récente est disponible. Ces données sont utilisées pour calculer les estimations nationales et infranationales de la mortalité infantile et des moins de cinq ans pour les périodes de cinq ans précédant l’enquête. Ces estimations peuvent ensuite être projetées sur l’année de début du SMSS (pour la mortalité de référence) à l’aide d’une estimation des tendances de la mortalité, telle que celle issue des estimations modélisées des Nations unies11 ou d’une estimation empirique fiable et raisonnable des tendances de la mortalité. L’estimation de la taille de l’échantillon tient compte des paramètres de précision (marge d’erreur) ainsi que de l’aspect pratique, avec la nécessité de garantir la qualité, la durabilité et l’accessibilité financière des données. Les indicateurs clés qui intéressent le SMSS sont les taux de mortalité néonatale, infantile, des moins de cinq ans et des adultes, ainsi que les fractions et les taux de causes de décès associées. La taille de l’échantillon et le nombre de grappes reflètent la nécessité d’une précision ou d’une marge d’erreur adéquate pour ces indicateurs sur une période de référence, de préférence annuelle, et des domaines de mesure tels que les provinces/régions. Bien qu’il soit souhaitable de donner à l’échantillon la puissance nécessaire pour détecter les variations annuelles des taux de mortalité et des taux de mortalité par cause dans chaque domaine, cela conduirait à une taille d’échantillon importante et non viable, en particulier dans les provinces/régions où le fardeau de la mortalité est faible. Pour des indicateurs tels que le taux de mortalité maternelle, il peut être utile d’envisager des estimations infranationales calculées sur une période d’au moins deux ans afin de garantir une taille d’échantillon suffisamment importante pour l’estimation. La précision de la taille de l’échantillon peut être estimée en termes d’erreur type relative en pourcentage (ETRP). Le choix de l’ERSP dépendra du niveau d’estimation de la mortalité, en gardant à l’esprit que des marges d’erreur plus faibles donneront un nombre important et peu pratique de grappes. En fonction des indicateurs de mortalité du pays, des besoins et des demandes du gouvernement, certaines zones infranationales (par exemple, certaines régions/provinces à mortalité élevée ou faible) peuvent faire l’objet d’un suréchantillonnage afin de générer des estimations annuelles du taux de mortalité et des estimations précises des fractions et des taux de mortalité par cause spécifique. Nous recommandons de revoir et de réviser la taille de l’échantillon tous les 3 à 5 ans afin de garantir que les statistiques démographiques produites ont une précision acceptable. La disponibilité d’un nouveau recensement de la population offre l’occasion de procéder à de telles révisions, notamment en prenant des mesures pour corriger et augmenter l’échantillon SMSS afin qu’il continue à être représentatif des domaines statistiques sélectionnés.
Exemple illustratif de calcul de la taille de l’échantillon
Souvent, un intérêt marqué pour le suivi de la mortalité chez les enfants de moins de cinq ans, le taux de mortalité des moins de cinq ans (TMM5), peut être utilisé pour estimer la taille globale de l’échantillon. Pour la surveillance communautaire des naissances et des décès, le TMS5 est souvent estimé en divisant le nombre annuel de décès d’enfants de moins de cinq ans par le nombre annuel de naissances. Ainsi, un modèle de probabilité binomiale constitue une bonne approximation pour le calcul de la taille de l’échantillon. Cette approche est prudente et permettra également d’obtenir un échantillon suffisant pour d’autres taux de mortalité spécifiques à l’âge. La formule suivante peut être utilisée pour estimer la taille de l’échantillon par domaine.
Paramètres > - m = taux de mortalité de référence > - d = marge d’erreur souhaitée (souvent appelée « précision ») > - α = niveau de confiance, généralement fixé à 0,05 > - deff = effet de conception > - f = taux de non-réponse (au niveau des ménages) > - CBR = taux brut de natalité > - h = taille moyenne des ménages > - c = nombre moyen de ménages par grappe
Le nombre estimé de naissances annuelles est obtenu par :
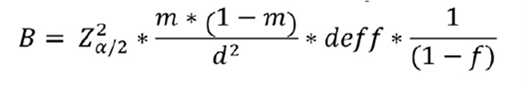
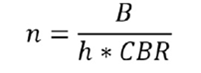
Le nombre correspondant de grappes N est obtenu comme suit :
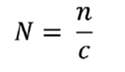
S’il existe plusieurs domaines, pour obtenir une taille d’échantillon satisfaisante et réalisable, il faudra assouplir la marge d’erreur en réduisant la précision de l’estimation. Alors qu’au niveau national , la taille de l’échantillon serait suffisante pour estimer les taux de mortalité avec une bonne précision, une fois ventilée par domaine, la précision sera considérablement réduite.
Calcul de la taille de l’échantillon pour COMSA/SIS-COVE
L’estimation de la taille de l’échantillon était basée sur le taux de mortalité infantile (TMI) projeté dans chaque province jusqu’en 2016, en utilisant le taux de réduction annuel estimé par Le Groupe interinstitutions des Nations Unies pour l’estimation de la mortalité infantile (UN-IGME) entre 2000 et 2010. Les estimations du TMI ont été obtenues à partir de l’EDS 2011. Nous avons utilisé 7 décès pour 1 000 naissances vivantes comme marge d’erreur dans les quatre provinces présentant la mortalité des moins de cinq ans la plus élevée, ce qui correspond à une marge d’erreur relative (marge d’erreur absolue divisée par le TMI) comprise entre 11 % et 17 %. Dans toutes les autres régions, nous avons utilisé une marge d’erreur relative comprise entre 25 % et 30 %. Sur la base de ces hypothèses, le nombre total de grappes pour le SMSS a été estimé à 700. Avec le taux de mortalité infantile prévalent, on s’attendait à un total annuel de 2 649 décès d’enfants de moins de cinq ans, 1 805 décès de nourrissons et 9 230 décès. Dans chacune des quatre provinces les plus touchées, le taux de mortalité infantile estimé en 2016 varie entre 72 et 90 décès pour 1 000 naissances vivantes et peut être mesuré avec une marge d’erreur de ±8 pour 1 000 naissances vivantes.
Les colonnes du tableau ci-dessous sont les suivantes: Colonne 1 : Province Colonne 2 : Taux de mortalité infantile (TMI) (DHS 2011) Année de référence = 2007, Colonne 3 : TMI prévu à l’horizon 2016* Colonne 4 : Marge d’erreur relative Colonne 5 : Marge d’erreur absolue (TMI) (2SE) Colonne 6 : Nombre annuel de naissances, Colonne 7 : Estimation du nombre annuel de décès d’enfants de moins de cinq ans Colonne 8 : Estimation de la mortalité infantile annuelle Colonne 9 : Estimation du nombre de ménages Colonne 10 : Estimation du nombre de zones de recensement du système d’enregistrement par échantillonnage (300 ménages/zone de recensement), Colonne 11 : Estimation de la population totale dans les grappes Colonne 12 : Estimation du nombre total de décès
Table 1 : Calcul de la taille de l’échantillon pour COMSA/SIS-COVE
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Inhambane | 0.039 | 0.026 | 29% | 0.007 | 2516 | 92 | 64 | 14845 | 49 | 61362 | 614 |
| Nampula | 0.041 | 0.027 | 29% | 0.008 | 2390 | 101 | 64 | 16009 | 53 | 58290 | 583 |
| Maputo City | 0.061 | 0.040 | 25% | 0.010 | 2132 | 108 | 85 | 10651 | 36 | 52009 | 520 |
| Maputo Province | 0.068 | 0.045 | 25% | 0.011 | 1904 | 116 | 85 | 10668 | 36 | 46432 | 464 |
| Niassa | 0.061 | 0.040 | 25% | 0.010 | 2132 | 136 | 85 | 12033 | 40 | 52009 | 520 |
| Sofala | 0.073 | 0.048 | 25% | 0.012 | 1767 | 117 | 85 | 8551 | 29 | 43103 | 431 |
| Gaza | 0.063 | 0.041 | 25% | 0.010 | 2062 | 143 | 85 | 10746 | 36 | 50289 | 503 |
| Manica | 0.064 | 0.042 | 17% | 0.007 | 4550 | 328 | 191 | 25405 | 85 | 110977 | 1110 |
| Cabo Delgado | 0.082 | 0.054 | 13% | 0.007 | 5758 | 422 | 309 | 33933 | 113 | 140439 | 1404 |
| Tete | 0.086 | 0.056 | 12% | 0.007 | 6022 | 491 | 339 | 31948 | 106 | 146882 | 1469 |
| Zambezia | 0.095 | 0.062 | 11% | 0.007 | 6611 | 593 | 412 | 35304 | 118 | 161239 | 1612 |
| Total | 37844 | 2649 | 1805 | 210093 | 700 | 923031 | 9230 |